Brian and I have been hard at work the past week figuring out how to make CourtListener able to understand more that one document type. Our goal right now is to make it possible to add:
- oral arguments and other audio content,
- video content if it’s available,
- content from RECAP, and
- thousands of ninth circuit briefs that Resource.org has recently scanned
The problem with our current database is that it’s not organized in a way that supports linkages between content. So, if we have the oral argument and the opinion from a single case, we have no way of pointing them at each other. Turns out this is a sticky problem.
The solution we’ve come up with is an architecture like the following:
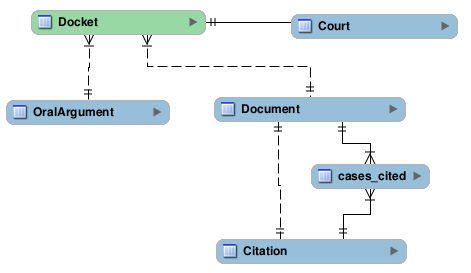
(we also have a more detailed version and an editable version)
And eventually, this will also have a Case table above the docket that allows multiple dockets to be associated with a single case. For now though, that’s moot, as we don’t have anyway of figuring out which dockets go together.
The first stage of this will be to add support for oral arguments, since they make a simple case to work with. Once that’s complete the next stage will be either to add the RECAP documents or those from Resource.org.
URLs
Since this is such a big change, we’re also taking this opportunity to re-work our URLs. Currently, they look like this:
/$court/$alpha-numeric-id/case-name-of-the-case/
For example:
https://www.courtlistener.com/scotus/yjn/roe-v-wade/
A few things bug me about that. First, it doesn’t tell you anything about what kind of thing you can expect to see if you click that link. Second, the alpha-numeric ID is kind of lame. It’s just a reference to the database primary key for the item, and we should just show that value (in this case, “yjn” means “108713”). To fix both of these issues, the new URLs will be:
/opinion/$numeric-id/case-name/
So:
https://www.courtlistener.com/opinion/108713/roe-v-wade/
That should be easier to read and should tell you what type of item you’re about to look at. Don’t worry, the old URLs will keep working just fine.
And the rest of the new URLs will be:
/oral-argument/$numeric-id/case-name/
/docket/$numeric-id/case-name/
and eventually:
/recap/$numeric-id/case-name/
API
We expect these changes to come with changes to the API, so we’ll likely be releasing API version 1.1 that will add support for dockets and oral arguments.
The current version 1.0 should keep working just fine, since we’re not changing any of the underlying data, but I expect that it will have some changes to the URLs and things like that. I’ll be posting more about this in the CourtListener dev list. as the changes become more clear and as we sort out what a fair policy is for the deprecation of old APIs.
I love getting feedback and comments. Make my day by making a comment.